Revista Bibliotecas Vol. XXX, No. 2 jul.-dic., 2012 pp.
Objetivo definir una clasificación de software libre para automatizar unidades de información basada en diferentes niveles. Para ello, se utilizan tres niveles previamente validados: automatización de catálogos, repositorios digitales y bibliotecas virtuales y automatización integral. Metodología: se definen los siguientes criterios para la clasificación de software: en español, especializado en el manejo documental y de acceso libre y disponible en Internet. Con base en estos criterios, se realizó una búsqueda bibliográfica, se consultó a expertos y en redes sociales. Gracias a esto, se construyó un catálogo de software. Resultados: con base en el catálogo obtenido, se creó un inventario clasificado de acuerdo con los niveles de automatización propuestos. Por otra parte, se logró determinar una subclasificación en el tercer nivel de automatización: unidades de información pequeñas, medianas y grandes. Esta subclasificación deriva de las capacidades técnicas y de seis variables puntuales relativas a las particularidades de las unidades de información donde se instalaría. Conclusiones: el inventario resultante constituye una valiosa herramienta para los proyectos de automatización al facilitar el estudio y evaluación de software por niveles, a la vez, ayuda a clarificar al profesional sobre qué es realmente lo que desea automatizar en su unidad de información.
Software libre, Automatización de bibliotecas, Bibliotecas virtuales, Repositorios digitales.
Objective: To define a classification of free software for automation of information units based on levels of automation. This is done using previously validated three levels: automated catalogs, digital repositories and virtual libraries, and full automation. Method: We define the following criteria for the classification of software: software in Spanish, specializes in document management and free and available online. Based on these criteria, we conducted a literature search were consulted subject matter experts and social networks. Because of this we built a software catalog. Results: Based on the catalog obtained, created an inventory classified according to the proposed levels of automation. Furthermore it was determined a sub in the third level of automation: information units small, medium and large. This subclassification is derived from the technical capabilities and six variables relating to the specific point of information units which would be installed. Conclusions: The resulting inventory is a valuable tool for automation projects to facilitate the study and evaluation of software levels, while the professional helps clarify what is really what you want to automate its information unit.
Free software, Automation of libraries, Virtual libraries, Digital repositories
Mucho se habla acerca de las tecnologías de la información y las telecomunicaciones (TIC), así como sobre su importancia en el desarrollo de un país. De hecho, existen múltiples índices de desarrollo que las utilizan como una variable determinante para definir la posición, en el ranking, de un país o región dentro. Esto lleva al estudio de su rol dentro de los distintos escenarios de la sociedad (Rodríguez, 2009).
Paradójicamente, las unidades de información (bibliotecas, centros de documentación, centros referenciales, etc.), a pesar de ser los proveedores del componente estratégico y la materia prima para el desarrollo de la Sociedad de la Información, se encuentran en el último lugar entre las prioridades de inversión en las organizaciones (Arriola y Butrón, 2008). Por otro lado, el costo del software comercial para la automatización integral de unidades de información (UI) continúa siendo sumamente elevado y sus requerimientos de equipo de cómputo implican grandes inversiones, lo cual desestimula la generación de proyectos de automatización. Generalmente, los grandes proyectos de inversión en el campo son realizados solamente por las universidades.
Desde siempre han existido alternativas de bajo costo para la automatización de las funciones en las bibliotecas. El Integrated Set of Information System (ISIS) fue desarrollado por la Organización Internacional del Trabajo en los años sesenta y se distribuyó mundialmente. Dicho software evolucionó, posteriormente, sobre los nuevos equipos con su versión MiniIsis y durante la década de los ochenta y de la mano de la UNESCO, se desarrolló el MicroIsis (o Micro CDS/ISIS) para microcomputadoras y sistema operativo MS-DOS (Mejía, 2010).
En los años noventa se creó una sencilla interfaz gráfica y se denominó finalmente WinIsis. Este programa fue actualizado por el proveedor, hasta la versión de Windows 95, mediante un parche para XP (versión 1.5b). En la actualidad, presenta grados de obsolescencia técnica significantivos; sin embargo, ha sido la punta de lanza en la labor de automatización de catálogos en las bibliotecas, a pesar de sus limitaciones. Gracias al empeño de muchos especialistas de diferentes campos, han surgido nuevas aplicaciones basadas en los principios del Software Libre que permiten la automatización integral de todos los servicios y procesos realizados en la UI y la generación de servicios agregados a la población usuaria, aunado a la posibilidad de desarrollo de bibliotecas virtuales.
La escogencia y la utilización de una aplicación dependerán, en gran medida, de los objetivos e intereses de la UI, así como de sus recursos. Si bien es cierto que con el software libre se pueden realizar proyectos de bajo costo, esto no significa que no existan costos de ningún tipo y siempre es necesaria cierta inversión en infraestructura tecnológica y recurso humano.
Esta investigación está dirigida a demostrar que existe una gran cantidad de programas destinados a colaborar en la automatización de UI o de algunos de sus módulos. Esto implica conceptos y procesos diferentes según las capacidades técnicas del software y de las necesidades de la UI; además, este artículo incluye una lista de programas especializados y clasificados, todos disponibles en idioma español.
Es importante mencionar que este artículo es parte de un proyecto de investigación cuyo alcance abarca la evaluación técnica de cada uno de estos programas orientados a la automatización de bibliotecas. No es posible realizar una clasificación del software existente sin tomar en cuenta los campos específicos de la automatización de UI a los que está destinado. Por ejemplo, algunos programas se especializan en el catálogo público; otros, en almacenamiento y recuperación de documentos digitales; otros más se orientan a la generación de bibliografías. Por tal motivo, no es posible equiparar todos los programas y clasificarlos de igual forma, ya que cada uno de ellos tiene sus propias particularidades.
Chinchilla (2011b) propone, para la clasificación de software, los siguientes niveles de automatización: primer nivel, automatización de catálogos; segundo nivel, repositorios digitales; y tercer nivel, automatización integral de bibliotecas. Para este último nivel, es importante establecer una subclase, según se trate de bibliotecas grandes, medianas o pequeñas. Sobre dicha clasificación, una vez validada, es que se pretende categorizar cada uno de los programas que aquí se presentan.
Con el fin de delimitar el software evaluado, se definieron tres criterios básicos: a) software en español o multilingüe con la opción de español, b) especializado en el manejo documental y c) de acceso abierto y disponible en Internet. Con base en dichos criterios se realizó una búsqueda bibliográfica en diferentes fuentes sobre el tema (véase la bibliografía), en aras de identificar los programas por evaluar. Por otra parte, se realizaron consultas a especialistas y discusiones en las redes sociales.
Una vez confeccionado un catálogo preliminar de software, se procedió a revisar varias propuestas de clasificación. Zúrita (2010) no propone una clasificación propiamente dicha, sino que agrupa programas en tres apartados: sistemas integrales para bibliotecas, aplicaciones para servicios de información digital y complementos y extensiones para la gestión bibliotecaria. Esta agrupación es de gran interés; dentro de su tercer agrupamiento incluye los sistemas de gestión de contenido, los cuales no son especializados en gestión documental, además de que los mezcla con los sistemas de control bibliográfico y automatización de catálogos.
Chinchilla (2011b) realiza una propuesta y es la que se desea validar y determinar su funcionalidad. Para probar su utilidad, se realizó el foro La aplicación del software libre en la automatización de Unidades de Información documental”, en el marco de las IV Jornadas de Investigación de la Escuela de Bibliotecología y Ciencias de la Información, de la Universidad de Costa Rica (celebradas en diciembre de 2011). Participaron cuatro panelistas especializados en el tema de la automatización de unidades de información. Tres de los panelistas contaban con una amplia experiencia en alguno de los niveles propuestos; el cuarto panelista era un experto en software libre. Al discutir la clasificación propuesta, se concluyó que, efectivamente, es funcional5. Por tanto, el software seleccionado para esta investigación será clasificado de acuerdo con esta propuesta.
La revisión de los niveles de automatización permitió construir un inventario del software. Es importante hacer notar que al revisar las generalidades de cada programa y tomando en cuenta la unidad de información donde podría ser implementado, se han identificado tres subniveles para el nivel 3: software para UI pequeñas, software para UI medianas y software para UI grandes. Esta tipología será explicada más adelante.
3.1. Primer nivel: automatización de catálogos
Este nivel se refiere al software especializado en control bibliográfico y automatiza, específicamente, el módulo de catalogación. Proporciona interfases de consulta al catálogo, implementando filtros, definición de criterios espacio-temporales y la construcción de consultas complejas por medio de búsquedas booleanas. Por lo general, son programas pequeños, utilizan motores de base de datos no relacionales y con poca demanda de recursos informáticos.
El módulo de catalogación se compone de una base de datos con una única tabla, en la que se almacena toda la descripción bibliográfica, de acuerdo con una definición de campos diseñada de forma libre por el programador o utilizando algún formato de intercambio de información, por ejemplo, MARC21. La implementación de tablas de autoridades representa un problema, ya que es necesaria la creación de bases de datos externas con la información descrita, para luego establecer relaciones “artificiales” entre tablas. Se habla de relaciones artificiales debido a que no se están dando relaciones entre tablas de una misma base de datos, sino entre tablas de bases de datos independientes, utilizando una aplicación intermedia.
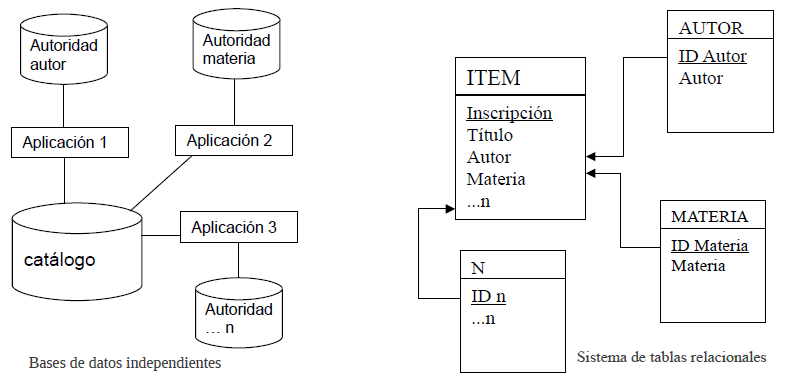
La figura 1 esquematiza la diferencia entre los sistemas de bases de datos independientes y el sistema relacional. Para lograr establecer comunicación entre la base de datos del catálogo y las bases de las autoridades, es necesario contar con aplicaciones que simulen una relación. Este esquema, por lo tanto, puede resultar ineficiente al requerir uniones artificiales y mantener los datos separados y generar redundancias innecesarias, con el consecuente consumo de recursos y el aumento de las posibilidades de errores e inconsistencias.
Por su parte, el sistema de base de datos relacional contiene los datos en una única base y establece relaciones entre ellos por medio de tablas. De esta forma, la tabla Ítem simplemente hace referencia a los datos de las tablas de autoridades (autoridad de autor, autoridad de materia, autoridad n) por medio de llaves foráneas.
Es importante indicar que de los catálogos automatizados se han extraído una gran cantidad de productos bibliográficos derivados, tales como bibliografías especializadas, catálogos colectivos, reseñas, entre otros. Por tal motivo, los catálogos siguen constituyendo un elemento de gran valor en de las unidades de información. El cuadro 1 describe cada uno de los programas incluidos en esta categoría.





Fuente: elaboración propia
3.2. Segundo nivel: repositorios de información
Los programas incluidos en este nivel se especializan en el almacenamiento y la recuperación de documentos digitales. Por lo general, constan de una base de datos y una interfase de búsqueda sobre la Web, amigable e intuitiva, además de una serie de servicios de valor agregado a la información almacenada. Para la descripción y posterior recuperación de los documentos se emplean metadatos, que son estructuras de descripción de la información almacenada. Daudinot (2006, s.p.) ofrece cuatro razones para fundamentar la utilización de metadatos en la descripción de los documentos:
- Los metadatos facilitan la descripción de recursos no textuales e información binaria, como: audio, software, imágenes, vídeos, etc., esto supone una ventaja con respecto a la indización automática dirigida solo a texto.
- Los metadatos deben proporcionar instrumentos para describir el contenido semántico de un recurso y están mejor preparados para soportar la recuperación de información que el propio documento. En muchos casos, los recursos de información no son capaces de facilitar por sí mismos sus propias relaciones semánticas. Por ejemplo, un código de un programa no puede facilitar cuál es su utilidad si no dispone de una caracterización (metadatos) en la que se describa.
- La existencia de gran cantidad de recursos electrónicos no textuales en Internet, justifica la necesidad de que existan sistemas de recuperación de información en la red basados en metadatos.
- Una categoría especial de metadatos que hace que los sistemas que los utilizan presenten una ventaja comparativa en la recuperación frente a los que buscan sobre el texto completo, son los metadatos sobre recursos que no son fácilmente accesibles porque están ocultos (protegidos por contraseñas) o que son accesibles solo por medio de protocolos específicos (Internet invisible). Estos metadatos deben publicarse de forma que los programas que indizan sobre ellos puedan acceder fácilmente a su metainformación.
Por otra parte, según Daudinot (2006, s.p.), el formato para la implementación de metadatos especializado en documentos digitales es el Dublin Core9, el cual describe la información de un archivo digital por medio de 15 etiquetas:

Un repositorio constituye un elemento de gran importancia para el almacenamiento y recuperación en línea de documentos. Sin embargo, requiere de componentes adicionales para convertirse en una biblioteca virtual. El término virtual implica la simulación de la realidad física (Saorín, 2002, p.61), por lo que adicionado a un repositorio de documentos se requiere de productos, servicios y recursos de información adicionales. Chinchilla (2011a) menciona , en su propuesta de diseño de la biblioteca virtual del Centro Centroamericano de Población de la Universidad de Costa Rica, productos específicos como bases de datos bibliográficas, de texto completo, mapoteca virtual, entrega de documentos, cartelera de eventos, enlaces a material de interés y acceso a publicaciones periódicas electrónicas.
Sin embargo, para recrear la propuesta de Saorín, son requeridos aún más servicios de valor agregado, tales como referencia virtual, diseminación selectiva de información, búsquedas en múltiples bases de datos en tiempo real y de manera transparente a la población usuaria, de forma tal que se pueda cumplir con el postulado que indica que “la Biblioteca Virtual es un servicio completo de biblioteca real en un entorno telemático” (Saorín, 2002, p.63).
Zamora (2009, p.12), por su parte, ofrece una amplia gama de elementos que deben ser cubiertos, al indicar que:
La biblioteca virtual debe proveer acceso instantáneo y conexión electrónica a bibliotecas, personas, instituciones, y empresas de todo el mundo, a la vez que brinda acceso a un amplio rango de recursos intelectuales, no limitado a los textos tradicionales, disponibles en los sistemas de información, como también a bases de datos de texto e imagen, objetos multimedia, a través de una interfaz interactiva, todo desde un único punto de acceso: el escritorio del usuario.

Fuente: elaboración propia
3.3. Tercer nivel de automatización: automatización integral
Este nivel está compuesto por sistemas que gestionan todas las áreas sustantivas de una biblioteca: adquisiciones, catalogación, publicaciones periódicas, consulta, circulación y administración general. Algunos módulos pueden incluir aplicaciones específicas como referencia electrónica, consulta web y generador de reportes estadísticos. Debido a su construcción modular, utilizan bases de datos relacionales para su integración. Además, basan sus definiciones de metadatos en estándares internacionales como MARC21 y Dublin Core, inclusive de formatos de intercambio como Z30.50.
Como se mencionó con antelación, al definir el tercer nivel, se determinó que existen tres subniveles. Dichos subniveles van asociados tanto a las capacidades técnicas como a 6 variables puntuales, referentes a las particularidades de la unidad de información donde se instalaría:
· Tipo de Unidad de Información. · Tamaño de la colección. · Tipo de materiales que maneja. · Cantidad y tipo de usuarios y de usuarias que atiende · Recurso humano con que cuenta. · Capacidad técnica y económica.
De acuerdo con esta subclasificación, es recomendable catalogar el software de este nivel en tres: a) software para bibliotecas pequeñas, b) software para bibliotecas medianas y c) software para bibliotecas grandes. Por tal motivo, la indicación de que un determinado software es aplicable a alguna de las subclasificaciones indicadas dependerá de una valoración inicial de la UI. Esta clasificación del software en cada uno de los subniveles mencionados se realizaría de acuerdo con las siguientes variables técnicas:
· Robustez del motor de base de datos que utiliza el software. · Parametrización dinámica de las funciones del software para adaptarse a diferentes escenarios técnicos organizacionales. · Complejidad de la plataforma en la que se encuentra desarrollado el software. · Requerimientos del hardware y del software. · Calidad del soporte técnico brindado al software. · Facilidad de desarrollo de nuevos requerimientos. · Interoperabilidad con otras aplicaciones de software. · Manejo de estándares internacionales para la importación y la exportación de datos.

Fuente: elaboración propia.
1. El recurso humano técnico de buena calidad, en cualquier proyecto de automatización de unidades de información, es una parte imprescindible para el éxito del proyecto. Ahora bien, la consecución del recurso humano técnico con conocimiento de software libre es más difícil y, por lo tanto, más oneroso que el requerido para proyectos con software licenciado de uso común.
2. La subclasificación de un software, correspondiente al tercer nivel en las categorías de biblioteca pequeña, mediana o grande, es una recomendación técnica relativa al conocimiento de los autores, pero nunca una limitación. Así, por ejemplo, un software recomendado para una biblioteca grande podría ser implementado en una biblioteca pequeña, con la salvedad de que esto implicará un mayor esfuerzo técnico y administrativo para la implementación de la aplicación, ya que se requiere de un personal más capacitado y de mayores costos. Esta decisión dependerá de la visión y los objetivos que tenga la biblioteca donde se implementará el software.
3. Los niveles de automatización constituyen una herramienta muy útil para clasificar el software orientado a la automatización de unidades de información, tal como fue aplicado en la fase preliminar del proyecto de investigación citado y expuesto en este artículo. Esta herramienta facilita el estudio y una evaluación de software comparable, ya que de otra manera se podría caer en el error de analizar y contrastar software con propósitos diferentes a la tarea de automatización de unidades de información.
4. En general, el software libre citado requerirá de mayores costos de capacitación para el personal operativo de la biblioteca, por cuanto el desconocimiento de este es mayor que el del licenciado de uso común. En Costa Rica no se tiene una cultura orientada al uso de software libre, por lo que la adaptación técnica y operativa hacia el uso y explotación de este involucra costos adicionales de capacitación y motivación.
5. Este estudio no pretende ser una lista absoluta del posible software a utilizar en cada uno de los niveles expuestos, ya que al ser un estudio que plantea propuestas está sujeto a constante cambio, tanto por el surgimiento de nuevos programas como por el desconocimiento de algunos, ya sea por su poca presencia en el mercado o por una omisión involuntaria de los autores. El artículo se propone como una guía válida para coadyuvar en la selección e implementación de software de acuerdo con los criterios técnicos que establezcan el nivel de automatización perseguido por una biblioteca. Además, que el estudio y la elaboración de este artículo están limitados al alcance del proyecto de investigación expuesto en la metodología aplicada y que se limita al software libre en español, disponible en la WEB y orientado al manejo documental.
6. Esta propuesta se basa en las bondades que ofrecen el acceso al software de forma libre, el acceso al código fuente y la posibilidad de modificación y adaptación de este a las necesidades de la unidad de información. No se basa, por lo tanto, en la suposición de que no existe costo alguno, ya que los costos asociados al hardware, al personal técnico informático y a la capacitación se mantienen. Incluso, respecto al personal técnico, podrían incrementarse debido a que la disponibilidad de este tipo de personal en el mercado es escasa y por ende, más onerosa.
1 Recibido el 9 de mayo de 2012, aprobado el 1 de octubre de 2012.
2 Investigador del Centro Centroamericano de Población, director de la revista Población y Salud en
Mesoamérica y profesor e investigador de la Escuela de Bibliotecología y Ciencias de la Información de la
Universidad de Costa Rica.
3 Profesor e investigador de la Escuela de Bibliotecología y Ciencias de la Información de la Universidad de
Costa Rica.
4 http://www.facebook.com/groups/softwarefree/
5La memoria de las IV Jornadas de Investigación pude ser consultada en:
http://www.ebci.ucr.ac.cr/archivos/IVjornadas/Ponencias/Memoria_digital.zip
6En el caso específico del WinIsis, al momento de generar el archivo invertido, se requiere de gran cantidad
de memoria principal. Sin embargo, una vez efectuado este proceso, los requerimientos vuelven a ser
mínimos.
7 http://sourceforge.net/projects/coronita/
8 http://malete.org/Doc/Selene
9 http://dublincore.org/
10 http://www.gnu.org/s/gdbm/